数据系统的基本介绍
数据系统的基础
从数据系统架构的角度出发
OLAP和OLTP
在企业中,通常会有两类的数据工作者,一种是后端开发人员另一种则是数据分析师。后端开发人员通常通过构建服务来处理读取和更新数据的请求,这些服务通常直接或者间接的为外部用户提供服务;数据分析师则是通常对过去一段时间内的所有业务数据做分析,产出关于组织活动的报告以及对业务新的见解。
由上可知,数据系统主要分为两个大类,即 OLAP(On-Line Analytical Processing)和 OLTP(On-Line Transcations Processing)
| 属性 | 事务型系统(OLTP) | 分析型系统(OLAP) |
|---|---|---|
| 主要读取模式 | 点查询(通过键获取单个记录) | 对大量记录进行聚合 |
| 主要写入模式 | 创建、更新和删除单个记录 | 批量导入(ETL)或事件流 |
| 人类用户示例 | Web 或移动应用程序的最终用户 | 内部分析师,用于决策支持 |
| 机器使用示例 | 检查操作是否被授权 | 检测欺诈/滥用模式 |
| 查询类型 | 固定的查询集,由应用程序预定义 | 分析师可以进行任意查询 |
| 数据代表 | 数据的最新状态(当前时间点) | 随时间发生的事件历史 |
| 数据集大小 | GB 到 TB | TB 到 PB |
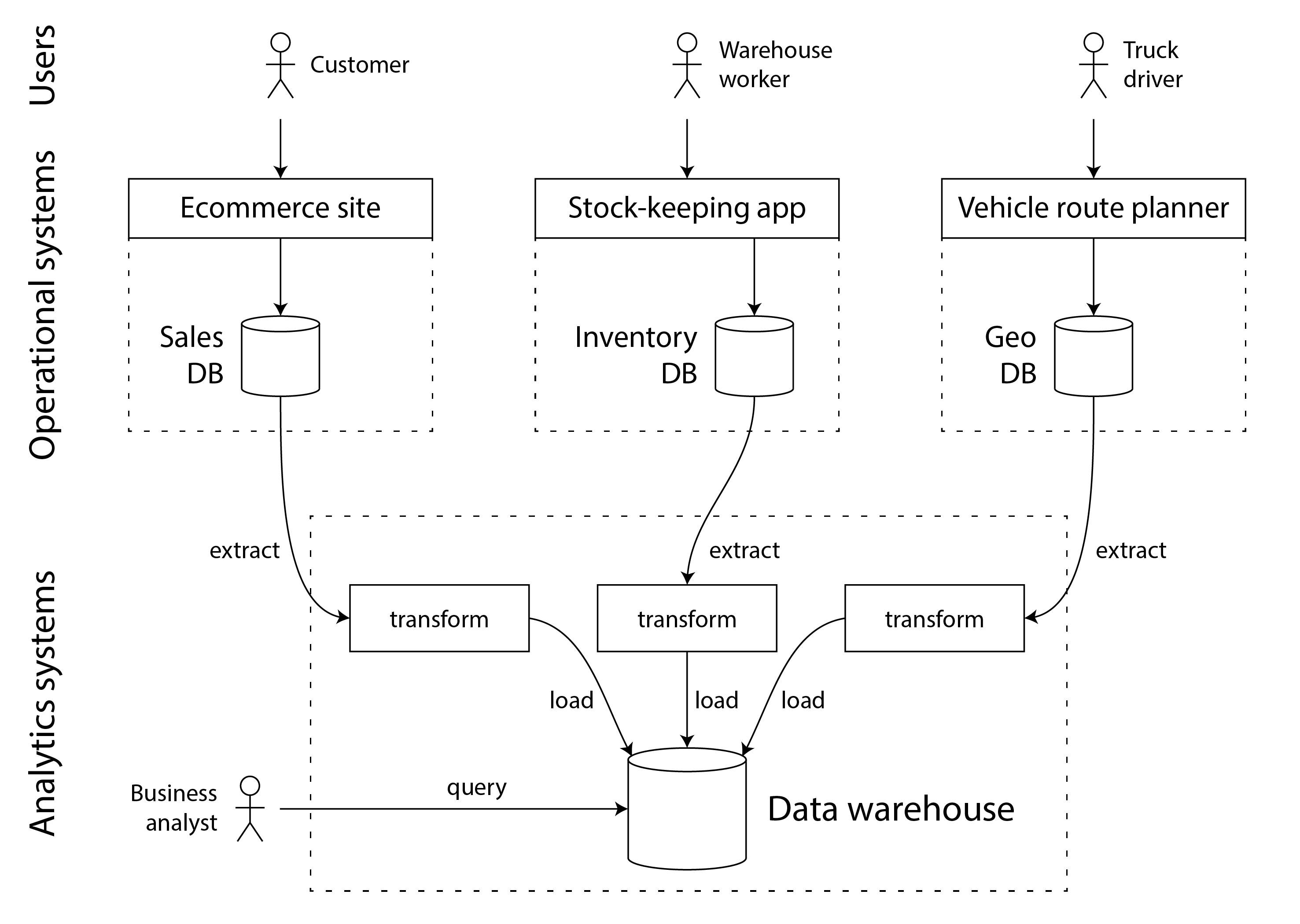
数据仓库(Data WareHouse)
早期的数据库基本都是OLTP类型的设计,包括数据分析也在其上执行。而OLTP在大数据分析上的劣势,使得越来越多的企业转而在单独的数据库系统上运行分析。这个单独的数据库被称为 数据仓库。
数据仓库中的数据通过从OLTP型数据库中ETL而来,显而易见,数据仓库中保存着的是OLTP的只读副本。
数据湖(Data Lake)
从数据仓库的介绍中,很容易可以发现,数据仓库只适合存储结构化的数据,而往往除了业务数据,还有日志,流式事件等数据也想要保存。这些数据的明显特点是结构不清晰,数据仓库只能存结构化数据的局限性被无限放大,由此开始推出了数据湖。
由于数据仓库的局限性,在数据湖里,与数据仓库的区别在于,数据湖只是包含文件,并且干脆就直接不强制任何特定的文件格式或数据模型。数据湖的数据来源也不再只是ETL(这里新提出了CDC的概念,增量数据更新,即OLAP一旦由数据更新,就触发向数据湖的写入),可以是像Kafka这种的流式输入,可以是系统各个组件的日志输入等等。此外,传统的数据仓库使用着HDFS,它开始渐渐不适合数据湖的存储需求,因为有着更好拓展,更便宜,更好用的对象存储可以选择(S3/MinIO/OSS)。
湖仓一体(Lakehouse)
在数据湖被推出后,人们很快发现,数据入湖并不能很好的解决所有的问题,数据湖中存储的是原始的数据,如果缺乏严格的数据管理,那么就很容易变为“数据沼泽”。于是在数据湖之上,开发者开始提供类似数据仓库的能力(ACID、Schema等),也可以被称作数据存储中间层。现有的开源存储中间层有Iceberg,Hudi和Delta,它们是通过表格式+元数据+事务日志的方式在湖中文件上,将它们组织为可以进行管理的表。
Iceberg
最大的特点是对数据进行分区,并且拥有很好的元数据管理。同时最开放最通用,在数据查询上有独特的优势。适合多平台的查询以及数据的分析
Hudi
Hudi全称(Hadoop Upserts anD Incrementals)。虽然是基于HDFS发展的,但是hudi也可以支持对象存储。此外HUDI原生支持 Upsert、Delete、增量读(Incremental Query),适合大量实时写入、CDC、需要增量消费的业务事实表。
Delta
主要面向 Spark / Databricks 生态,擅长流批一体,最贴近使用原生SQL的中间层。使用Spark进行流处理的时候很具有优势。
讲到这里,其实上面只是涉及到了设计的部分,而现实的落地也同样的复杂。
从数据系统落地的角度出发
众所周知,公司是要赚钱的。大家公认的管理智慧是,作为组织核心竞争力或竞争优势的事物应该在内部完成,而非核心、例行或常见的事物应该留给供应商。因此采用云服务还是云原生就是一个问题。
Cloud Service 和 Cloud Native
使用云服务而不是自己运行对应的软件,本质上是将该软件的运维外包给云提供商。 使用云服务有充分的支持和反对理由。云提供商声称,使用他们的服务可以节省你的时间和金钱,并相比自建基础设施让你更敏捷。(客户与服务商会达成SLA,里面就约定了服务的质量,可用性等约束)
云服务的缺点:
- 服务不可用时你做不了任何事
- 架构的调整,必须要和服务商先行沟通
- 数据安全的一系列问题
使用云原生就能很好的解决上面的痛点。基于云原生的服务,基本的要求就是:高可用(容忍故障,人为错误),可伸缩,可观测。
云原生的缺点:
- 学习成本高
- 运维复杂性高,微服务治理成本高
- 由于云原生的自动化特性,不合理的分配资源会导致浪费
分布式与单节点系统
涉及多态机器通过网络通信的系统会被称之为分布式系统,参与分布式系统的每个进程被称之为节点。采用分布式系统的原因无外乎有以下几种需求:
- 高可用性
- 可伸缩性
- 延迟
- 弹性
- 。。。
不过分布式系统也存在着很大的问题:部分故障仍然是分布式系统面临的最大问题,而且每个通过网络的请求和调用都会存在着失败的可能性。
总结
在大数据领域,很多问题并没有标准的答案,现有的各种解决方案更像是一个利弊权衡下来的结果。在本章中,可以看到OLTP和OLAP的区别;以及数据仓库到数据湖乃至湖仓一体的发展;还有云服务和云原生,分布式和单节点系统的对比。可以看到,数据系统的架构式多样的,最终采用什么样的技术选型还是要回归到需求上面。