Java语言基础
Java程序基础
类型
Java的类型分为两大类,分别是基本数据类型和引用类型
- 基本数据类型:byte, short, int, long, float, double, char
- 引用类型:除了上述的基本数据类型,其它所有的类型都是引用类型. 其中,数组Array也是引用类型
数组的使用:
Java和C++略有不同,其中数组的声明是以类型+[]的形式.
1 | //声明一个int类型的int数组 |
需要注意的是:
如果对数组进行 Arrays.sort方法排序,如果存储的类型是基本的数据类型,那么会直接对存储的数据做操作,如果是引用的类型的话,并不会直接移动在JVM中实际的存储位置,而是会只对其引用做排序.
面向对象基础
面向对象的基础即三个:封装,多态,继承. 所有面向对象的知识都是围绕这三个展开的
类(class)和实例(instance)
类是对现实世界进行抽象来映射到计算机模型的产物.而实例则是依据类实例化的产物. 类也可以理解为对一个概念的封装
就好比:人是一个抽象概念,而笔者则是人的一个实例
字段(feilds)和方法(method)
字段和方法从UML中的定义去理解可能会更加的简单.即字段是属性,而方法则是操作
使用方法就要使用参数,这里对方法的参数作出介绍:
要强调的是: 参数如果是基本类型,那么会在存储位置直接作出修改;如果是引用类型,那么传递的实际上是引用的地址
- 方法参数: 方法可以包括0个或者多个参数,调用方法的时候参数必须一一对应传递
- 可变参数: 和CPP 17之后引入的折叠表达式一样, 使用
类型...定义. - this变量: 这里我个人倾向放在方法中来讲,因为每个方法都能访问到this变量,可以理解为隐藏在方法内的参数
提到方法,有一种特殊的方法,是用来创造实例的,即构造(construct). 如果一个类没有申明任何一个构造函数,那么Javac会默认实现一个构造函数. 如果你一但申明了构造函数,那么Javac就不会这么做. 这里和C++有很大的不同,GCC是一定默认生成构造函数的.
继承(inheritance)
首先要明确的是, 为了避免cpp中多继承产生的很多问题, 在Java所有的继承都是单继承. 提到继承, 就必须要提类的访问权限控制.Java 一共有四种访问控制级别,如下表所示
| 修饰符 | 当前类 | 同一包 | 子类(不同包) | 其他包 | 说明 |
|---|---|---|---|---|---|
| public | ✅ 可访问 | ✅ 可访问 | ✅ 可访问 | ✅ 可访问 | 最宽松,所有地方都能访问 |
| protected | ✅ 可访问 | ✅ 可访问 | ✅ 可访问 | ❌ 不可访问 | 子类可以访问(即使在不同包),但普通外部类不行 |
| **(default)**无修饰符 | ✅ 可访问 | ✅ 可访问 | ❌ 不可访问 | ❌ 不可访问 | 又叫包级私有,同包内可见 |
| private | ✅ 可访问 | ❌ 不可访问 | ❌ 不可访问 | ❌ 不可访问 | 最严格,只能在本类中访问 |
继承的使用时机:
在面向对象的课程中,老师都介绍过三种对象之间关系的概念:
- is-a : 代表着类与类之间是继承关系,这时就要使用
extends或者implements - has-a: 代表着类与类之间是组合或者聚合关系,这个时候则是要在字段
feilds中添加 - uses-a: 代表着类与类之间是一种依赖关系,这时经常出现在方法
method的参数中,表示依赖
三者的关联程度从高到低依次排序为: is-a; has-a; uses-a
上面已经介绍了继承的具体使用时机
super
在Java中, super关键字代表这父类(超类), 和this关键字类似,可以使用super关键字访问父类的字段和方法. 需要注意是的在子类的构造函数中,首先一定会调用父类的构造函数,否则子类一定会构造失败. 很多时候并没有看见super()方法,这是因为父类如果有默认的构造函数,那么在子类中就不用声明,否则一定要使用父类的构造函数
final
在Java中, final修饰符号可以用来修饰类, 方法, 变量
- final 修饰类 : 表示阻止继承, 不允许任何类继承这个类
- final 修饰方法 : 表示这个方法在继承之后不允许被重写
- final 修饰变量: 表示这个变量不允许被修改(和C++中的const一个作用,不过java中没有const)
总之,在不同的场景下, final的意思略有不同,需要注意区分
向上转型和向下转型
- 向上转型: 显然向上转型是安全且一定成功的, 因为子类会继承父类所有的字段. 本质上向上转型是做了抽象,来满足OOP需求
- 向下转型: 向下转型是不安全且不一定成功的, 向下转型一定要用
instanceof判断
多态(Polymorphism)
多态分为静态多态和动态多态, 也叫做编译期多态(函数重载 overload)和运行期多态(函数重写 override)
- 函数重载: 函数名称要求必须一样, 返回值,参数要求可以不一样. 所有的函数重载都要写在一个类中
- 函数重写: 函数名称,返回值参数要求必须一样
静态多态是编译期决定的, 由编译器依据方法签名确定的;而动态多态,则是在运行时, 有JVM查找vtable来决定具体使用哪个方法
接口(interface)和抽象类(abstract class)
抽象类和接口的相同之处:
- 两者都不能被实例化, 都是定义某种规范
- 两者都能有抽象方法和非抽象方法, 不过接口中的非抽象方法一定是default的
不同之处:
- 抽象类更适合描述高层抽象概念是规则的制定者;而接口更像是一种特性一种标签. 实现了这个接口的类就表明有了这个这个特性(比如cloneable, comparable). 正因为如此, 所以一个类可以实现多个接口.
- 抽象类也是类,除了不能实例化, 它拥有类的所有功能
- 接口则不一样, 在接口中所有声明的字段都是
static final属性的, 即使你并没有写static final标识符.(即不能字段是不能实例化的)
总之, 抽象类和接口的界限不是很明显, 如果一个抽象类没有需要的实例字段, 就要声明为接口
内部类
Java的内部类分为三种: 内部类(innner class), 匿名类(anonymous class), 静态内部类(static Nested class)
内部类: 内部类与普通类有个最大的不同,就是Inner Class的实例不能单独存在,必须依附于一个Outer Class的实例。同样的, 内部类隐式的持有一个Outer.this的指针, 用来访问外部类的字段
匿名类:匿名类不需要在Outer Class中明确地定义这个Class,而是在方法内部,通过匿名类(Anonymous Class)来定义.
如下面两段代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15new Thread(new Runnable {
public void run() {
//do something
}
}).start();
Queue<String> pq = new PriorityQueue<>(new Comparator<String>() {
public int compare(String s1, String s2) {
return s1.length() - s2.length();
}
});这里的 Runnable 和 Comparator 都是接口, 显然接口是不能被实例化的, 这里就是使用了匿名类的方法
静态内部类: 静态内部类很特殊, 他可以不依附于外部的类, 便可以存在, 因此它无法访问到外部类的字段, 但是可以访问到外部类的
private静态的字段和方法, 以及间接的使用new构建一个外部类实例. 这是一种破坏封装性的豁免. 静态内部类常用于复杂对象的构造,工具类等等. 以及用来实现单例模式(懒汉式).1
2
3
4
5
6
7
8
9
10
11
12class Singleton{
/*
* fields and methods
*/
public static Singleton getInstance{
return Handler.INSTANCE;
}
static class Handler{
final static Singleton INSTANCE = new Singleton();
}
}
包(package), Jar, Classpath, 模块(Module)
- 包 : 包的作用是实现命名空间的功能, 同时包也是default访问级别的访问边界. 通过包, 可以更好的组织类,来避免命名冲突.
- Jar : 在java中, java程序的正确执行依赖.class能被jvm正确的识别到并且成功执行. 而jar包的作用就是管理分散在各层目录中的.class文件. 所以jar在jvm看来更像是一个目录. 通过ijar包可以灵活的部署代码
- classpath: classpath的作用是告诉JVM 应该去哪里寻找程序正确执行所需要的class
- 模块: 模块则是在包的基础上, 在加上了一层封装, 这样可以控制哪些包可以对外暴露, 即只有export的包才可以访问其public属性, 否则即使是public也无法访问.
Java的核心类介绍
String, StringBuilder, StringBuffer, StringJoiner:
这些类中, String 是无法修改的, 而 StringBuilder, StringBuffer是可以修改的, 前者是线程不安全而后者是线程安全的, StringJoiner则是用于字符串合并
包装类型
包装类型指的是Integer, Boolean这些类型, 它们是对基本数据类型的包装, 可以被置为null. 而对于包装的类型, 它们会自动发生装箱和拆箱, 这很影响效率. 并且包装类型的比较必须使用 equals()
JavaBean
名字上理解是咖啡豆, 实际上是一种特殊的类, 它专门为数据传输所设计. 他的所有的字段都是 private , 通过 public的 set和get方法来读写实例字段. 这样的类可以被成为JavaBean.
枚举类
这里和CPP类似, 传统的类中声明静态字段方法来枚举的话, 不具备每个枚举值的合法性. 因此特地的引入了枚举类. 首先Enum是无法被继承的, 然后枚举类编译器会对其值的合法性质做检查.
记录类
记录类是从Java 14之后引入的概念. 记录类的特点是 : 所有的字段都是 final 的, 一旦创建实例之后无法修改任何字段. 并且类的本身也是final的, 无法被继承.
Java的异常处理
在Java中, 使用异常来表示错误, 并且通过try…catch…来捕获异常. 在java中, 所有的异常都是通过继承Throwable类来实现的.整个异常的结构如下图所示
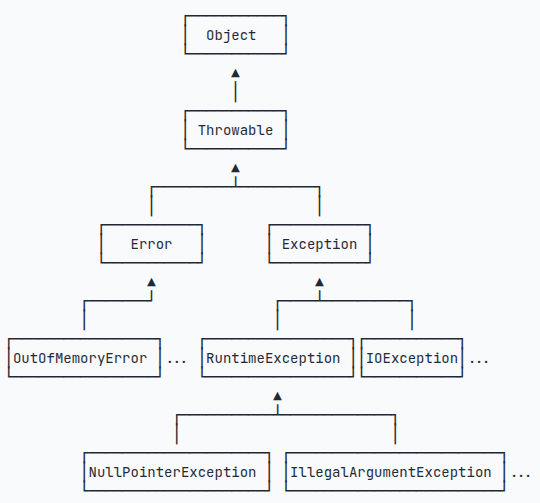
在上图中, Error是严重的错误, 比如内存耗尽, 栈溢出. 这些问题对于程序来说是无能为力的, 只能在终端查看backtrace的结果
而Exception是运行时候出现的错误, 他可以被捕获并且去处理. 所有的Exception 都必须要被捕获并且去处理
同时, 和异常处理所伴随的是日志, 在java标准库中提供了logging作为日志功能的基本实现. 同样的, 也有一些开源好用的日志库, 比如log4j, slf4j这些日志库.
总而言之, 使用日志和捕获异常是在编写大型项目很好的一个编程习惯. 一定要养成这样的习惯
反射(Reflection)
反射是Java很大的一个特性, 区别于CPP(不过听说CPP也要引入反射了…), 反射是Spring中AOP的基石
Class类
JVM为每个加载的 class创建了对应的 Class实例,并在实例中保存了该 class的所有信息,包括类名、包名、父类、实现的接口、所有方法、字段等(这些信息也叫做),因此,如果获取了某个 Class实例,我们就可以通过这个 Class实例获取到该实例对应的 class的所有信息。通过 Class实例获取 class信息的方法称为反射(Reflection)
每个实例都可以通过使用getClass()的方法来获取自身的Class实例
在使用反射的时候,需要注意的是: Java是动态加载的, 只有在运行时jvm第一次读到这个类才会为这个类添加对应的Class类实例
通过反射访问字段:
Class类提供了以下几个方法来获取字段:
- Field getField(name):根据字段名获取某个public的field(包括父类)
- Field getDeclaredField(name):根据字段名获取当前类的某个field(不包括父类)
- Field[] getFields():获取所有public的field(包括父类)
- Field[] getDeclaredFields():获取当前类的所有field(不包括父类)
需要注意的是, 如果字段是private的, 表明是受访问权限保护不可修改的. 那么需要使用 setAccessible来破坏其封装性
通过反射调用方法:
可以通过 Class实例获取所有 Method信息。Class类提供了以下几个方法来获取 Method:
Method getMethod(name, Class...):获取某个public的Method(包括父类)Method getDeclaredMethod(name, Class...):获取当前类的某个Method(不包括父类)Method[] getMethods():获取所有public的Method(包括父类)Method[] getDeclaredMethods():获取当前类的所有Method(不包括父类)
需要注意的是, 如果方法是private的, 那么和字段一样,需要使用 setAccessible来破坏其封装性.
调用反射需要使用 invoke(Object instance, Object... parameters), 注意, 对于反射调用的非静态方法一定是依赖于实例的,而静态方法则只要传入null作为第一个参数即可
通过反射调用构造方法:
同样, 也可以通过Class实例去获取类的构造方法
getConstructor(Class...):获取某个public的Constructor;getDeclaredConstructor(Class...):获取某个Constructor;getConstructors():获取所有public的Constructor;getDeclaredConstructors():获取所有Constructor。
通过获取的 construction对象, 调用其 newInstance方法即可按照指定构造函数创造实例
获取继承关系
- 获取父类的Class :
getSuperclass(): 获取某个Class类型的父类的Class实例 - 获取实现的Interface:
getInterfaces(): 获取某个Class类型所实现的所有接口的Class 实例 - 判断继承关系:
- 判断一个实例是否是某个类型时,使用
instanceof操作符 - 判断两个
Class实例中,有一个向上转型是否成立,使用isAssignableFrom()操作
- 判断一个实例是否是某个类型时,使用
注解(Annotation)
Java 注解是一种 元数据机制,它的作用是 在编译期或运行时向工具或框架提供额外信息,从而实现 编译检查、代码生成、运行时依赖注入/映射、文档生成 等功能。
定义注解
@Tareget:定义Annotation能够被应用于源码的哪些位置: 类, 方法, 字段, 参数等等@Retention:定义Annotation的生命周期, 仅编译期, 仅Class文件, 运行期@Repeatable:使用@Repeatable这个元注解可以定义Annotation是否可重复@Inherited:使用@Inherited定义子类是否可继承父类定义的Annotation
这里给出一个定义注解的实例
1 |
|
处理注解
之前提到过, 注解需要在编译期或运行时向工具提供额外信息, 这就需要反射的机制. 因此, Java通过反射来处理注解
- Class.getAnnotation(Class)
- Field.getAnnotation(Class)
- Method.getAnnotation(Class)
- Constructor.getAnnotation(Class)
不过, 如果需要使用反射来读取类型, 那么注解的生命周期要选为运行时
泛型(Generics)
在Java中, 泛型可以概括为, 通过编写一个模板代码来进行任意类型的适配, 是一种多态的体现. 与CPP中的模板不同, CPP的模板能力更为强大, 它能在编译期展开并且根据传入的类型生成不同的实例. 而在Java中, 编译时会检查泛型的类型安全,但在 编译后的字节码中泛型类型信息会被擦除. 及在JVM看来, List<Integer> 和 List<String>其实是同一个类 List(没有类型参数的原始),只是编译阶段保证你不会把错误的类型放进去。
编写和使用泛型
在使用泛型的时候, 必须将T替换为所需要的class类型. 注意, 这里的T只能是引用类型, 因此不能是int这种基本类型. 因为Java泛型的实现基础是类型擦除, 而 int 不用继承 Object类实现.
在编写泛型的时候, 需要注意的是静态方法不能直接引用泛型类型T, 必须定义其它的类型. 也很好理解, 静态的方法和类是否实例化是无关的
类型擦除
类型擦出是泛型的底层实现, 其实JVM对泛型一无所知, 因为在编译期间, 编译器通过类型擦除将所有的泛型安全的转化为别的类型.
比如下面是一段泛型代码:
1 | class Box<T> { |
而在经过类型擦除之后, 结果是:
1 | class Box { |
显然, 下面这段代码在JVM看来是没有任何泛型的信息
类型擦除的影响
- 运行时没有泛型信息:
1 | List<String> list1 = new ArrayList<>(); |
- 不能直接创建泛型数组: 运行时JVM是无法区分
List<String>和List<Integer>的数组
1 | List<String>[] array = new List<String>[10]; // 编译错误 |
- 不能用泛型做
instanceof判断
1 | if (obj instanceof List<String>) { } // 编译错误 |
- 反射需要用Type来获取精确的泛型消息
1 | List<String> list1 = new ArrayList<>(); |
PECS原则
何时使用 extends,何时使用 super?为了便于记忆,因此产生了PECS原则:Producer Extends Consumer Super。即:如果需要返回 T,它是生产者(Producer),要使用 extends通配符;如果需要写入 T,它是消费者(Consumer),要使用 super通配符
集合(Collections)
Java 的集合(Collection)是对一组对象进行存储、操作的容器类库,位于 java.util 包中。它们主要用来 代替数组,解决数组固定大小、操作不灵活的问题。
集合分为三大类:
- Collection 接口(存放单个元素)
List:有序、可重复Set:无序、不可重复Queue/Deque:队列/双端队列
- Map 接口(存放键值对
key-value)- 不能直接继承
Collection,但也属于集合框架的一部分
- 不能直接继承
- 工具类
Collections:操作集合的工具类(排序、搜索、线程安全化等)Arrays:操作数组的工具类(与集合转换)
下面是集合的大分类
1 | Iterable |
需要注意的是,在使用这些collections的时候, 对放入集合的元素有着如下的要求:
哈希类集合(HashMap/HashSet 等)依赖 equals 和 hashCode
有序/排序集合(TreeMap/TreeSet 等)依赖 Comparable 或 Comparator