k8s的服务与负载均衡
Service的定义
在k8s中, Service是一种kuberenets对象, 它的作用是将运行在一个或一组 Pod 上的网络应用程序公开为网络服务的方法
端口
在service中,主要有三种端口:
- port :Service 对外暴露的端口(集群内部访问用的 ClusterIP:port,或 NodePort/LoadBalancer 的端口)。
- targetPort :Pod 容器内实际监听的端口。(target端口如果不写就是和port一个端口)
- nodePort :如果 Service 类型是 NodePort/LoadBalancer,会在宿主机节点开放一个固定端口(30000–32767 默认范围)。
selector
在service中, 既然要组织一组pod来提供服务, 那么必须要提供一种表示来匹配pod, 那么这里就是使用了selector.
1 | apiVersion: v1 |
如上述代码就是一个简单的service定义, 里面通过run:my-nginx来匹配符合标签的pod, 来加入service之中
endpointslice
在定义service的时候, 如果使用了selector, 那么会自动生成EndpointSlice对象, 每个 EndpointSlice 里包含若干个 Pod/Endpoint 的信息,例如:
- 地址 (addresses) → Pod 的 IP
- 端口 (ports) → Pod 容器的端口(对应 Service 的 targetPort)
- 条件 (conditions) → Pod 是否 Ready、Serving、Terminating 等
- 拓扑信息 (topology) → 节点、区域等信息,方便拓扑感知调度
服务类型
Kubernetes Service 类型允许指定你所需要的 Service 类型。
可用的 type 值及其行为有:
ClusterIP通过集群的内部 IP 公开 Service,选择该值时 Service 只能够在集群内部访问。这也是没有为 Service 显式指定type时使用的默认值。可以使用 Ingress或者 Gateway API 向公共互联网公开服务。NodePort通过每个节点上的 IP 和静态端口(NodePort)公开 Service。为了让 Service 可通过节点端口访问,Kubernetes 会为 Service 配置集群 IP 地址,相当于你请求了type: ClusterIP的 Service。LoadBalancer使用云平台的负载均衡器向外部公开 Service。Kubernetes 不直接提供负载均衡组件;你必须将 Kubernetes 集群与云平台集成, 比如阿里云ExternalName将服务映射到externalName字段的内容(例如,映射到主机名api.foo.bar.example)。该映射将集群的 DNS 服务器配置为返回具有该外部主机名值的CNAME记录。集群不会为之创建任何类型代理。
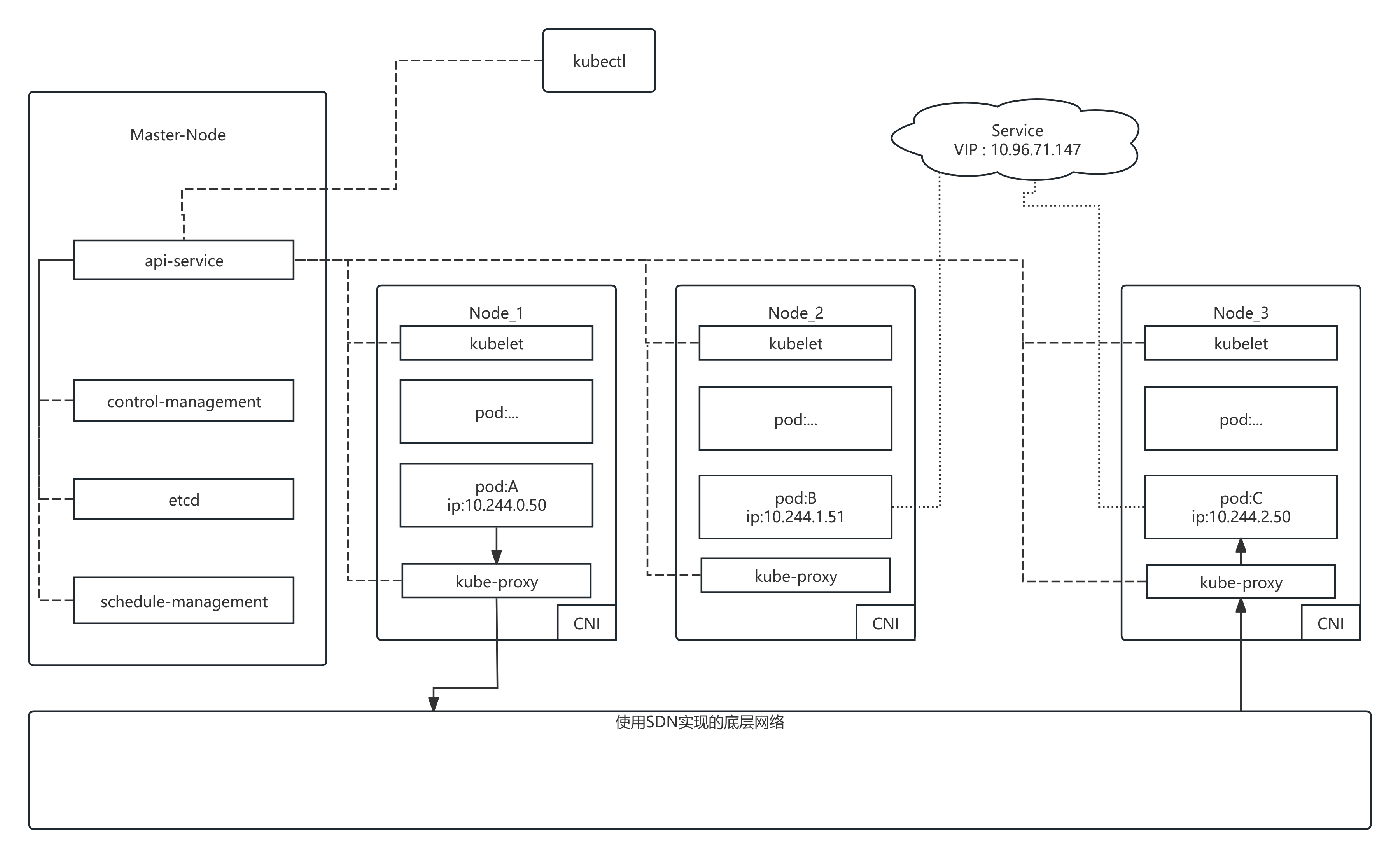
service的使用
在实际使用service的时候, service并不是实际存在的实体, 比如pod这种, 而是一种抽象的概念. 如下图是一个k8s网络的示意图
Pod的创建
controller-manager (比如 DeploymentController、ReplicaSetController)会监听 apiserver 中 Pod/ReplicaSet/Deployment 的变化, 来动态的管理pod的数量. 分别是几种情况:
kubectl发送的直接创建pod请求:
- 首先api-service 会作合法性判断, 通过后会第一时间把对象存入etcd
- scheduler (kube-scheduler)通过 watch 监听 apiserver 中的 Pending Pod 。会根据调度策略(资源可用性、亲和性/反亲和性、污点和容忍度等)为 Pod 选定一个合适的 Node。选好后 scheduler 向 apiserver 发送 绑定请求 ,把 Pod.spec.nodeName 设置为选中的节点。apiserver 更新 etcd,Pod 状态还是
Pending,但已经绑定到某个 Node。 - 目标节点上的 kubelet 会 watch apiserver 上自己节点的 Pod 对象, 发现有一个新 Pod 分配到本节点,于是开始创建流程. 包括创建puase容器, 调用CNI分配网络,拉取镜像,启动业务容器. 在完成这些过程中, kubelet会定期向api-service汇报自己的状态
- api-service会接受来自 kubelet 报告的状态, 并且更新etcd. 同时control-manager中的endpoints-controller会在service创建, pod状态变化时候扫描集群里所有 Pod, 来做标签匹配. 满足所有条件的 Pod → 被写入 EndpointSlice
pod的创建被包裹在deployment或者statefulset之中:
- 首先api-service 会作合法性判断, 通过后会第一时间把deployment或者statefulset对象存入etcd
- 这时候controller-manager中的deployment-controller或者statefulset-controller会监听apiserver中deployment或者statefulset的变化, 两者通常会实现一个ReplicaSet。而ReplicaSetController 监听 ReplicaSet 的变化后, 也会触发相应的Pod创建流程, 之后的流程就走到了scheduler,kubelet等组件.
Pod丢失或者宕机:
- controller-manager 发定期访问api-service来检查pod状态, 一旦发生确实, 就进入创建的过程. 详细见上面第二步